DSA 内存中的链表
计算机内存
为了解释链表是什么,以及链表与数组的区别,我们需要了解一些关于计算机内存工作原理的基础知识。
计算机内存是程序运行时使用的存储空间。这是你的变量、数组和链表存储的地方。
内存中的变量
让我们假设我们想在变量 myNumber 中存储整数 "17"。为了简化,我们假设这个整数存储为两个字节(16 位),并且 myNumber 在内存中的地址是 0x7F30。
0x7F30 实际上是存储 myNumber 整数值的两个字节内存中的第一个字节的地址。当计算机访问 0x7F30 来读取整数值时,它知道必须读取第一个和第二个字节,因为在这个特定的计算机上整数是两个字节。
下图显示了变量 myNumber = 17 在内存中的存储方式。
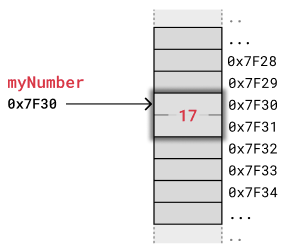
上面的例子展示了在简单但流行的 Arduino Uno 微控制器上如何存储整数值。这个微控制器具有 8 位架构和 16 位地址总线,整数和内存地址使用两个字节。相比之下,个人电脑和智能手机使用 32 位或 64 位来存储整数和地址,但内存的工作方式基本相同。
内存中的数组
为了理解链表,先了解数组在内存中的存储方式是有益的。
数组中的元素在内存中是连续存储的。这意味着每个元素都存储在前一个元素的正后面。
下图显示了整数数组 myArray = [3,5,13,2] 在内存中的存储方式。我们在这里使用一种简单的内存,每个整数占用两个字节,就像前面的例子一样,只是为了说明这个概念。
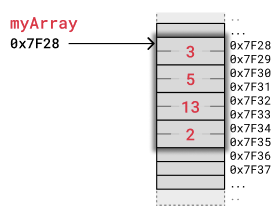
计算机只知道 myArray 第一个字节的地址,所以要通过代码 myArray[2] 访问第 3 个元素,计算机从 0x7F28 开始,跳过前两个整数。计算机知道一个整数占用两个字节,所以它从 0x7F28 向前跳 2x2 字节,并在地址 0x7F32 处读取值 13。
在数组中删除或插入元素时,所有后面的元素都必须向上移动以给新元素腾出空间,或者向下移动以填补被删除元素的位置。这种移动操作非常耗时,并且可能在例如实时系统中引起问题。
下图显示了删除数组元素时元素如何移动。
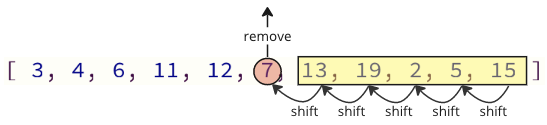
如果你在 C 语言中编程,那么操作数组也是你需要考虑的事情,因为在插入或删除元素时,你必须显式地移动其他元素。在 C 语言中,这不会在后台自动发生。
在 C 语言中,你还需要确保一开始为数组分配了足够的空间,以便以后可以添加更多元素。
你可以在 这个之前的 DSA 教程页面 上阅读更多关于数组的内容。
内存中的链表
与将数据集合存储为数组不同,我们可以创建一个链表。
链表在许多场景中都有使用,例如动态数据存储、栈和队列的实现或图表示,仅举几例。
链表由节点组成,节点包含某种数据,以及至少一个指向其他节点的指针或链接。
使用链表的一个主要优点是节点存储在内存中的任何可用空间中,节点不必像数组中的元素那样连续地存储在一起。链表的另一个优点是,在添加或删除节点时,列表中的其余节点不必移动。
下图显示了链表如何在内存中存储。链表有四个节点,值为 3、5、13 和 2,每个节点都有一个指向列表中下一个节点的指针。
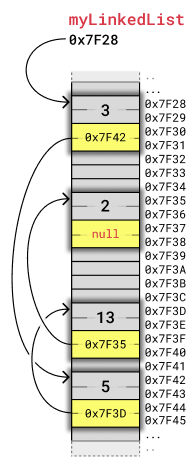
每个节点占用四个字节。两个字节用于存储整数值,两个字节用于存储指向列表中下一个节点的地址。如前所述,存储整数和地址所需的字节数取决于计算机的体系结构。这个例子,就像前面的数组例子一样,适合简单的 8 位微控制器架构。
为了更容易地看到节点之间的关系,我们将以一种更简单的方式显示链表中的节点,而不是与它们的内存位置相关联,如下面的图像所示。

如果我们使用这种新的可视化方法将前面例子中的四个节点放在一起,看起来是这样的。

正如你所见,链表中的第一个节点称为“头”(Head),最后一个节点称为“尾”(Tail)。
与数组不同,链表中的节点不直接放在内存中。这意味着在插入或删除节点时,不需要移动其他节点,这是一个优点。
链表的一个不太好的地方是,我们不能像访问数组那样直接访问节点,例如通过编写 myArray[5]。要访问链表中的第 5 个节点,我们必须从第一个节点“head”开始,使用该节点的指针访问下一个节点,并在此过程中跟踪已访问节点的数量,直到到达第 5 个节点。
学习链表有助于我们更好地理解内存分配和指针等概念。
在学习树和图等更复杂的数据结构之前,理解链表也很重要,因为这些数据结构可以使用链表来实现。
现代计算机中的内存
到目前为止,在本页中,我们使用了 8 位微控制器的内存作为示例,以使其简单易懂。
现代计算机中的内存原则上与 8 位微控制器中的内存工作方式相同,但存储整数和内存地址使用的内存更多。
下面的代码显示了我们在运行这些示例的服务器上整数的大小和内存地址的大小。
示例
用 C 语言编写的代码
#include <stdio.h>
int main() {
int myVal = 13;
printf("Value of integer 'myVal': %d\n", myVal);
printf("Size of integer 'myVal': %lu bytes\n", sizeof(myVal)); // 4 bytes
printf("Address to 'myVal': %p\n", &myVal);
printf("Size of the address to 'myVal': %lu bytes\n", sizeof(&myVal)); // 8 bytes
return 0;
}上面的代码示例仅在 C 语言中运行,因为 Java 和 Python 在特定/直接内存分配的抽象级别上运行。
C 语言中的链表实现
让我们实现前面提到的链表
让我们在 C 语言中实现这个链表,以查看链表在内存中存储的具体示例。
在下面的代码中,在包含库之后,我们创建了一个节点结构,它类似于一个类,代表了一个节点是什么:节点包含数据和指向下一个节点的指针。
函数 createNode() 为新节点分配内存,用作为函数参数给定的整数填充节点的 data 部分,并返回指向新节点的指针(内存地址)。
函数 printList() 只是用于遍历链表并打印每个节点的值。
在 main() 函数内部,创建了四个节点,将它们链接在一起,打印出来,然后释放内存。在使用完内存后释放内存是一个好习惯,以避免内存泄漏。内存泄漏是指内存在使用后未被释放,逐渐占用越来越多的内存。
示例
C 语言中的基本链表
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (!newNode) {
printf("Memory allocation failed!\n");
exit(1);
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}
void printList(Node* node) {
while (node) {
printf("%d -> ", node->data);
node = node->next;
}
printf("null\n");
}
int main() {
Node* node1 = createNode(3);
Node* node2 = createNode(5);
Node* node3 = createNode(13);
Node* node4 = createNode(2);
node1->next = node2;
node2->next = node3;
node3->next = node4;
printList(node1);
// Free the memory
free(node1);
free(node2);
free(node3);
free(node4);
return 0;
}要打印上面的代码中的链表,函数 printList() 使用“next”指针从一个节点移动到下一个节点,这称为链表的“遍历”。你将在“链表操作”页面上了解更多关于链表遍历和其他链表操作的内容。
Python 和 Java 中的链表实现
我们现在将使用 Python 和 Java 来实现相同的链表。
在下面的 Python 代码中,Node 类代表节点是什么:节点包含数据和指向下一个节点的链接。
该 Node 类用于创建四个节点,然后将这些节点链接在一起,最后打印出来。
正如你所见,Python 代码比 C 代码短得多,如果你只是想理解链表的概念,而不是链表在内存中的存储方式,Python 代码可能更好。
Java 代码与 Python 代码非常相似。单击下面的“运行示例”按钮,然后选择“Java”选项卡以查看 Java 代码。
示例
Python 中的基本链表
class Node:
def __init__(self, data):
self.data = data
self.next = None
node1 = Node(3)
node2 = Node(5)
node3 = Node(13)
node4 = Node(2)
node1.next = node2
node2.next = node3
node3.next = node4
currentNode = node1
while currentNode:
print(currentNode.data, end=" -> ")
currentNode = currentNode.next
print("null")
