DSA 合并排序
合并排序
合并排序算法是一种分治算法,它通过先将数组分解成更小的数组,然后以正确的方式将数组重新组合起来,使其有序。
速度
{{ msgDone }}分解:算法从将数组分解成越来越小的部分开始,直到一个子数组只包含一个元素。
合并:算法通过将最低值放在前面,将数组的小部分重新合并在一起,从而得到一个排序后的数组。
分解和构建数组以对其进行排序是通过递归完成的。
在上面的动画中,每次条形图被推下去都代表一次递归调用,将数组分成更小的部分。当条形图被抬起时,表示两个子数组已被合并在一起。
合并排序算法可以这样描述:
工作原理
- 将未排序的数组分成两个大小为原始数组一半的子数组。
- 只要当前数组部分包含的元素多于一个,就继续分解子数组。
- 通过始终将最低值放在前面,合并两个子数组。
- 持续合并,直到没有子数组为止。
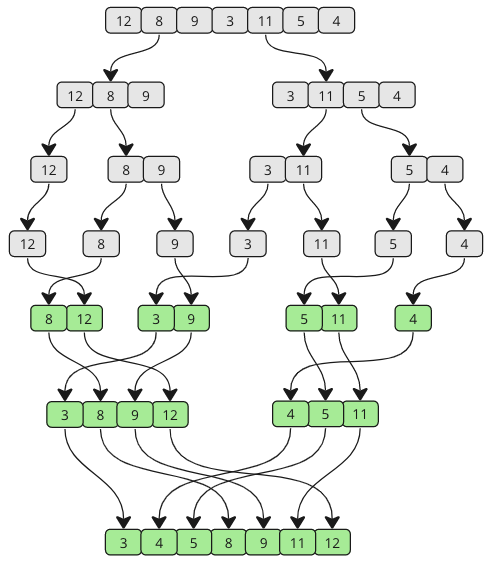
从不同的角度看看下面的图,了解合并排序的工作原理。正如你所见,数组被分解成越来越小的部分,直到重新合并。在合并过程中,会比较每个子数组中的值,以便最低的值排在前面。
手动演练
在实际用编程语言实现之前,让我们手动尝试排序,以便更好地理解合并排序的工作原理。
步骤 1:我们从一个未排序的数组开始,并且我们知道它会被分成两半,直到子数组只包含一个元素。Merge Sort 函数调用自身两次,一次用于数组的每个一半。这意味着第一个子数组将首先分解成最小的部分。
[ 12, 8, 9, 3, 11, 5, 4]
[ 12, 8, 9] [ 3, 11, 5, 4]
[ 12] [ 8, 9] [ 3, 11, 5, 4]
[ 12] [ 8] [ 9] [ 3, 11, 5, 4]
步骤 2:第一个子数组的分解完成,现在是合并的时候了。8 和 9 是要合并的前两个元素。8 是最小值,所以它排在第一个合并的子数组的 9 前面。
[ 12] [ 8, 9] [ 3, 11, 5, 4]
步骤 3:要合并的下一个子数组是 [ 12] 和 [ 8, 9]。两个数组中的值都从开始进行比较。8 小于 12,所以 8 排在前面,9 也小于 12。
[ 8, 9, 12] [ 3, 11, 5, 4]
步骤 4:现在第二个大的子数组被递归分解。
[ 8, 9, 12] [ 3, 11, 5, 4]
[ 8, 9, 12] [ 3, 11] [ 5, 4]
[ 8, 9, 12] [ 3] [ 11] [ 5, 4]
步骤 5:3 和 11 以它们显示的相同顺序合并在一起,因为 3 小于 11。
[ 8, 9, 12] [ 3, 11] [ 5, 4]
步骤 6:包含 5 和 4 的子数组被分解,然后合并,使 4 排在 5 前面。
[ 8, 9, 12] [ 3, 11] [ 5] [ 4]
[ 8, 9, 12] [ 3, 11] [ 4, 5]
步骤 7:右边的两个子数组被合并。进行比较以创建新合并数组中的元素。
- 3 小于 4
- 4 小于 11
- 5 小于 11
- 11 是最后剩余的值
[ 8, 9, 12] [ 3, 4, 5, 11]
步骤 8:最后剩余的两个子数组被合并。让我们更详细地看看比较是如何进行的,以便创建新的合并的、最终排序的数组。
3 小于 8
之前 [ 8, 9, 12] [ 3, 4, 5, 11]
之后:[ 3, 8, 9, 12] [ 4, 5, 11]
步骤 9:4 小于 8
之前 [ 3, 8, 9, 12] [ 4, 5, 11]
之后:[ 3, 4, 8, 9, 12] [ 5, 11]
步骤 10:5 小于 8
之前 [ 3, 4, 8, 9, 12] [ 5, 11]
之后:[ 3, 4, 5, 8, 9, 12] [ 11]
步骤 11:8 和 9 小于 11
之前 [ 3, 4, 5, 8, 9, 12] [ 11]
之后:[ 3, 4, 5, 8, 9, 12] [ 11]
步骤 12:11 小于 12
之前 [ 3, 4, 5, 8, 9, 12] [ 11]
之后:[ 3, 4, 5, 8, 9, 11, 12]
排序完成!
运行下面的模拟,以动画形式查看以上步骤。
{{ x.dieNmbr }}
手动运行:发生了什么?
我们看到该算法有两个阶段:首先是分解,然后是合并。
虽然可以在不使用递归的情况下实现合并排序算法,但我们将使用递归,因为这是最常见的方法。
在上面的步骤中我们看不到,但为了将数组分成两半,数组的长度除以二,然后向下取整得到一个称为“mid”的值。这个“mid”值用作分割数组的索引。
在数组被分割后,排序函数会用每个子数组调用自身,以便数组可以递归地再次分割。分割会一直持续到子数组只包含一个元素。
在 Merge Sort 函数的末尾,子数组被合并,因此在数组重新构建时,子数组始终是有序的。为了合并两个子数组并使其结果有序,会将每个子数组的值进行比较,并将最低值放入合并的数组中。之后,将比较两个子数组中的下一个值,将较低的值放入合并的数组中。
合并排序实现
要实现合并排序算法,我们需要:
- 一个包含需要排序的值的数组。
- 一个函数,它接受一个数组,将其分成两半,并用该数组的每个一半调用自身,以便数组一遍又一遍地递归分割,直到子数组只包含一个值。
- 另一个函数,它以排序的方式将子数组合并回在一起。
生成的代码如下:
示例
def mergeSort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
leftHalf = arr[:mid]
rightHalf = arr[mid:]
sortedLeft = mergeSort(leftHalf)
sortedRight = mergeSort(rightHalf)
return merge(sortedLeft, sortedRight)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
unsortedArr = [3, 7, 6, -10, 15, 23.5, 55, -13]
sortedArr = mergeSort(unsortedArr)
print("Sorted array:", sortedArr)在第 6 行,arr[:mid] 获取数组中直到索引“mid”之前的所有值(不包括该值)。
在第 7 行,arr[mid:] 获取数组中从索引“mid”开始的所有值以及之后的所有值。
在第 26-27 行,完成合并的第一部分。此时比较两个子数组的值,并且左子数组或右子数组为空,因此结果数组可以只用左子数组或右子数组的剩余值填充。这些行可以互换,结果将相同。
不使用递归的合并排序
由于合并排序是一种分治算法,因此递归是实现中最直观的代码。合并排序的递归实现也可能更容易理解,并且通常代码行数更少。
但是,合并排序也可以在不使用递归的情况下实现,这样函数就不会调用自身。
看看下面不使用递归的合并排序实现。
示例
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def mergeSort(arr):
step = 1 # Starting with sub-arrays of length 1
length = len(arr)
while step < length:
for i in range(0, length, 2 * step):
left = arr[i:i + step]
right = arr[i + step:i + 2 * step]
merged = merge(left, right)
# Place the merged array back into the original array
for j, val in enumerate(merged):
arr[i + j] = val
step *= 2 # Double the sub-array length for the next iteration
return arr
unsortedArr = [3, 7, 6, -10, 15, 23.5, 55, -13]
sortedArr = mergeSort(unsortedArr)
print("Sorted array:", sortedArr)
您可能会注意到,上面两个合并排序实现中的合并函数是完全相同的,但在上面的实现中,mergeSort 函数内的 while 循环用于替换递归。while 循环以原地方式完成数组的分割和合并,这使得代码有点难以理解。
简单来说,mergeSort 函数内的 while 循环使用较短的步长,使用 merge 函数对初始数组的微小部分(子数组)进行排序。然后增加步长以合并和排序数组的更大部分,直到整个数组被排序。
合并排序时间复杂度
有关时间复杂度的一般性解释,请访问此页面。
有关合并排序时间复杂度的更全面和详细的解释,请访问此页面。
合并排序的时间复杂度为:
\[ O( n \cdot \log n ) \]
对于不同种类的数组,时间复杂度几乎相同。无论数组是已排序还是完全打乱,算法都需要分割数组并将其合并回在一起。
下图显示了合并排序的时间复杂度。
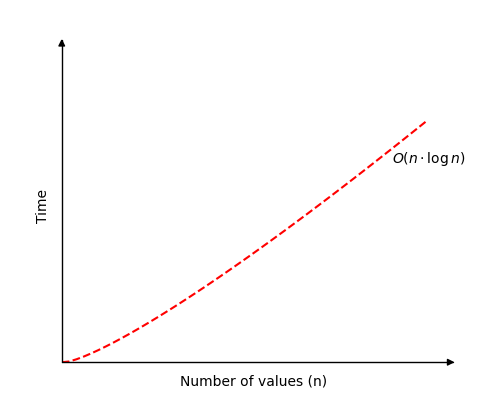
运行下面的模拟,对数组中的不同数量的值进行操作,并查看合并排序对 n 个元素的数组所需的次数是 O(n log n)。
{{ this.userX }}
操作次数:{{ operations }}
如果我们固定值的数量 n,则“随机”、“降序”和“升序”所需的操作次数几乎相同。
合并排序每次的表现几乎相同,因为数组是根据比较进行分割和合并的,无论数组是否已排序。

