机器学习 - Bootstrap Aggregation (Bagging)
在此页面上,W3schools.com 与 纽约数据科学学院 合作,为我们的学生提供数字培训内容。
Bagging
决策树等方法在训练集上容易过拟合,这可能导致在新数据上做出错误的预测。
Bootstrap Aggregation (Bagging) 是一种集成方法,旨在解决分类或回归问题中的过拟合问题。Bagging 旨在提高机器学习算法的准确性和性能。它通过对原始数据集进行有放回的随机抽样,并对每个子集拟合分类器(用于分类)或回归器(用于回归)。然后,通过多数投票(用于分类)或平均(用于回归)聚合每个子集的预测,从而提高预测准确性。
评估基础分类器
为了了解 Bagging 如何提高模型性能,我们必须首先评估基础分类器在数据集上的表现。如果您不了解决策树,请在继续之前回顾决策树课程,因为 Bagging 是该概念的延续。
我们将尝试识别 Sklearn 酒数据集中不同类别的葡萄酒。
让我们首先导入必要的模块。来自 sklearn 导入数据集
来自 sklearn.model_selection 导入 train_test_split
来自 sklearn.metrics 导入 accuracy_score
来自 sklearn.tree 导入 DecisionTreeClassifier
接下来,我们需要加载数据并将其存储到 X(输入特征)和 y(目标)中。参数 as_frame 设置为 True,这样在加载数据时就不会丢失特征名称。(sklearn 版本早于 0.23 必须跳过 as_frame 参数,因为它不支持)
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
为了在未见过的数据上正确评估我们的模型,我们需要将 X 和 y 分割成训练集和测试集。有关分割数据的信息,请参阅训练/测试课程。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
准备好数据后,我们现在可以实例化一个基础分类器并将其拟合到训练数据中。
dtree = DecisionTreeClassifier(random_state = 22)
dtree.fit(X_train,y_train)
结果
DecisionTreeClassifier(random_state=22)
我们现在可以预测未见测试集的葡萄酒类别,并评估模型性能。
y_pred = dtree.predict(X_test)
print("训练数据准确率:",accuracy_score(y_true = y_train, y_pred = dtree.predict(X_train)))
print("测试数据准确率:",accuracy_score(y_true = y_test, y_pred = y_pred))
结果
训练数据准确率:1.0
测试数据准确率:0.8222222222222222
示例
导入必要数据并评估基础分类器性能。
来自 sklearn 导入数据集
来自 sklearn.model_selection 导入 train_test_split
来自 sklearn.metrics 导入 accuracy_score
来自 sklearn.tree 导入 DecisionTreeClassifier
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
dtree = DecisionTreeClassifier(random_state = 22)
dtree.fit(X_train,y_train)
y_pred = dtree.predict(X_test)
print("训练数据准确率:",accuracy_score(y_true = y_train, y_pred = dtree.predict(X_train)))
print("测试数据准确率:",accuracy_score(y_true = y_test, y_pred = y_pred))
运行示例 »
基础分类器在数据集上的表现相当不错,在测试数据集上以当前参数(如果未设置 random_state 参数,可能会出现不同的结果)实现了 82% 的准确率。
现在我们有了测试数据集的基准准确率,我们可以看看 Bagging 分类器如何超越单个决策树分类器。
广告
创建 Bagging 分类器
对于 Bagging,我们需要设置参数 n_estimators,这是我们的模型将聚合的基础分类器数量。
对于这个样本数据集,估计器数量相对较低,通常会探索更大的范围。超参数调整通常通过网格搜索完成,但现在我们将使用一组选定的估计器数量值。
我们首先导入必要的模型。
来自 sklearn.ensemble 导入 BaggingClassifier
现在让我们创建一系列值来表示我们希望在每个集成中使用的估计器数量。
estimator_range = [2,4,6,8,10,12,14,16]
为了了解 Bagging 分类器在不同 n_estimators 值下的表现,我们需要一种方法来迭代这些值范围并存储每个集成的结果。为此,我们将创建一个 for 循环,将模型和分数存储在单独的列表中,以便后续可视化。
注意:BaggingClassifier 中基础分类器的默认参数是 DicisionTreeClassifier,因此在实例化 bagging 模型时无需设置它。
models = []
scores = []
for n_estimators in estimator_range
# 创建 bagging 分类器
clf = BaggingClassifier(n_estimators = n_estimators, random_state = 22)
# 拟合模型
clf.fit(X_train, y_train)
# 将模型和分数追加到各自的列表
models.append(clf)
scores.append(accuracy_score(y_true = y_test, y_pred = clf.predict(X_test)))
存储了模型和分数后,我们现在可以可视化模型性能的改进。
import matplotlib.pyplot as plt
# 生成分数与估计器数量的图表
plt.figure(figsize=(9,6))
plt.plot(estimator_range, scores)
# 调整标签和字体(使其可见)
plt.xlabel("n_estimators", fontsize = 18)
plt.ylabel("score", fontsize = 18)
plt.tick_params(labelsize = 16)
# 可视化图表
plt.show()
示例
导入必要数据并评估 BaggingClassifier 性能。
import matplotlib.pyplot as plt
来自 sklearn 导入数据集
来自 sklearn.model_selection 导入 train_test_split
来自 sklearn.metrics 导入 accuracy_score
来自 sklearn.ensemble 导入 BaggingClassifier
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
estimator_range = [2,4,6,8,10,12,14,16]
models = []
scores = []
for n_estimators in estimator_range
# 创建 bagging 分类器
clf = BaggingClassifier(n_estimators = n_estimators, random_state = 22)
# 拟合模型
clf.fit(X_train, y_train)
# 将模型和分数追加到各自的列表
models.append(clf)
scores.append(accuracy_score(y_true = y_test, y_pred = clf.predict(X_test)))
# 生成分数与估计器数量的图表
plt.figure(figsize=(9,6))
plt.plot(estimator_range, scores)
# 调整标签和字体(使其可见)
plt.xlabel("n_estimators", fontsize = 18)
plt.ylabel("score", fontsize = 18)
plt.tick_params(labelsize = 16)
# 可视化图表
plt.show()
结果
结果解释
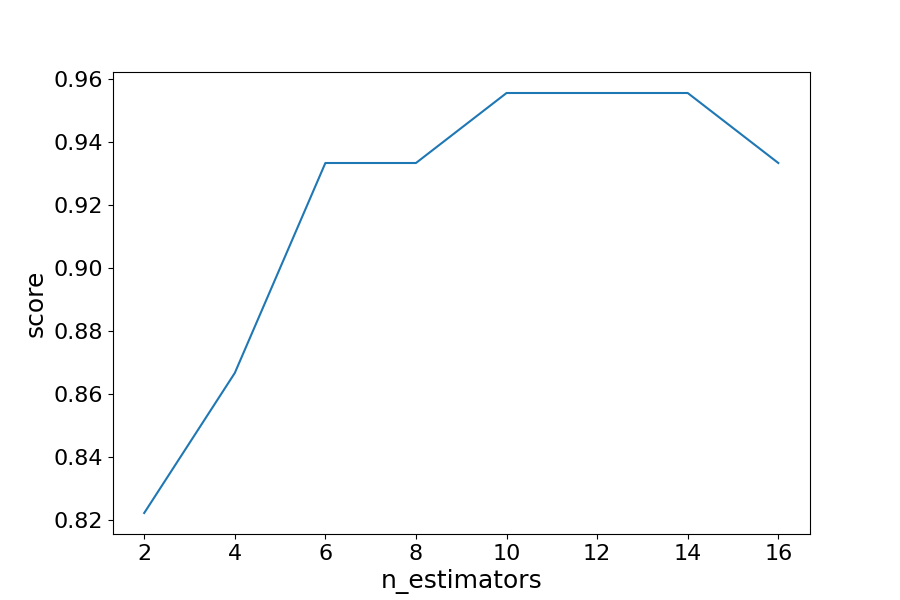
通过迭代不同数量的估计器,我们可以看到模型性能从 82.2% 提高到 95.5%。在 14 个估计器之后,准确率开始下降,同样,如果您设置不同的 random_state,您看到的值将有所不同。这就是为什么最好使用交叉验证来确保结果稳定。
在这种情况下,在识别葡萄酒类型时,准确率提高了 13.3%。
另一种评估形式
由于自举选择随机观测子集来创建分类器,因此在选择过程中会遗漏一些观测。这些“袋外”观测值可以用于评估模型,类似于测试集。请记住,袋外估计可能会高估二分类问题中的误差,并且应仅作为其他指标的补充。
在上次练习中,我们看到 12 个估计器产生了最高的准确率,所以我们将用它来创建我们的模型。这次将参数 oob_score 设置为 true,以使用袋外分数评估模型。
示例
使用袋外指标创建模型。
来自 sklearn 导入数据集
来自 sklearn.model_selection 导入 train_test_split
来自 sklearn.ensemble 导入 BaggingClassifier
data = datasets.load_wine(as_frame = True)
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
oob_model = BaggingClassifier(n_estimators = 12, oob_score = True,random_state = 22)
oob_model.fit(X_train, y_train)
print(oob_model.oob_score_)
运行示例 »
由于 OOB 中使用的样本和测试集不同,并且数据集相对较小,因此准确率存在差异。它们完全相同的情况很少见,OOB 应该作为估计误差的快速方法,但不是唯一的评估指标。
从 Bagging 分类器生成决策树
正如在决策树课程中看到的那样,可以绘制模型创建的决策树。还可以查看组成聚合分类器的各个决策树。这有助于我们更直观地理解 Bagging 模型如何得出预测。
注意:这仅适用于较小的数据集,其中树相对较浅且较窄,易于可视化。
我们需要从 sklearn.tree 导入 plot_tree 函数。可以通过更改您希望可视化的估计器来绘制不同的树。
示例
从 Bagging 分类器生成决策树
来自 sklearn 导入数据集
来自 sklearn.model_selection 导入 train_test_split
来自 sklearn.ensemble 导入 BaggingClassifier
来自 sklearn.tree 导入 plot_tree
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 22)
clf = BaggingClassifier(n_estimators = 12, oob_score = True,random_state = 22)
clf.fit(X_train, y_train)
plt.figure(figsize=(30, 20))
plot_tree(clf.estimators_[0], feature_names = X.columns)
结果
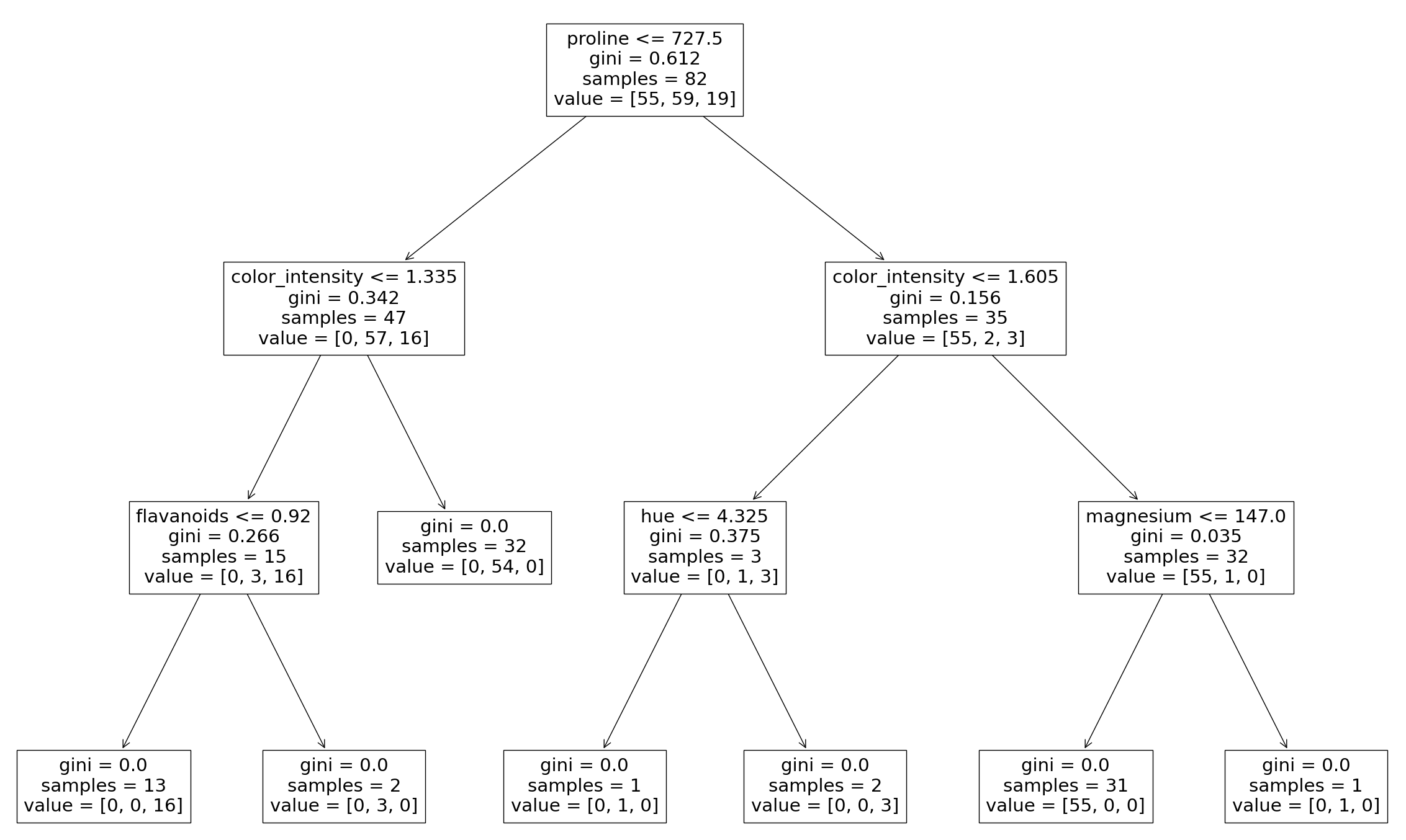
这里我们只看到第一个决策树,它用于对最终预测进行投票。同样,通过更改分类器的索引,您可以查看已聚合的每个树。

